How to use the Old Hungarian Concordance
1. First steps
The Old Hungarian Concordance (OHC) can be used with Firefox browser, version 12 or newer.
1.1. An introductory example
How many times does the Old Hungarian jonhom (my heart) word form occur in the corpus?
- Write jonhom in the Normalised (n) field.
- Press the OK button. After that, the appropriate query appears in the text area at the bottom of the page.
- Go to the Format field placed on the right side and select 'frequency list'. Below that, select the 'normalised (n)' option from the drop-down menu of Display.
- Run the query by pressing the Submit button.
The result appears in a new window: the given word form occurs four times in the corpus.
1.2. Components of the interface
The structure of the OHC interface is shown below.
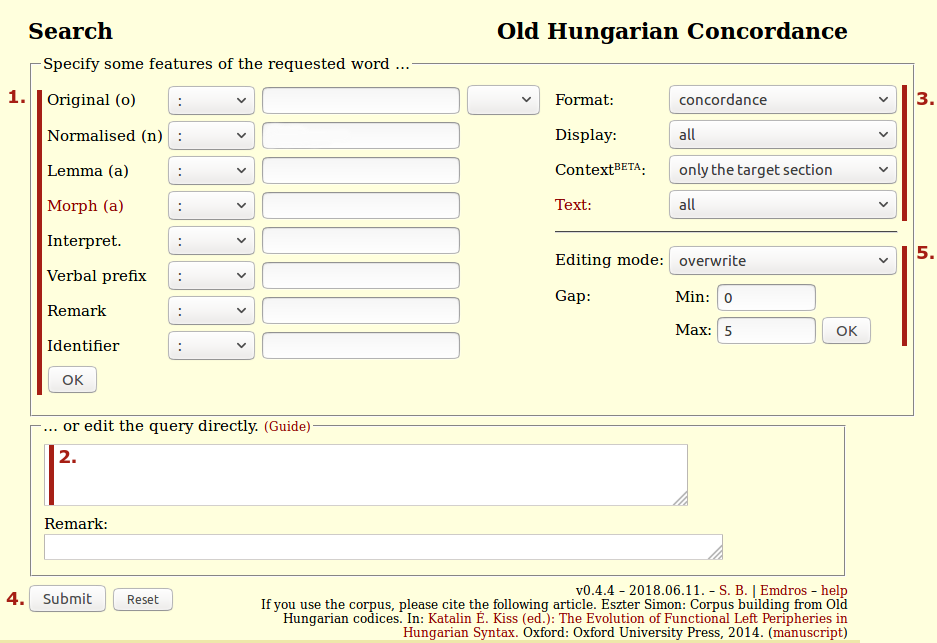
- The different features of the needed word can be specified on the left side of the upper box.
- The appropriate query is compiled in the text area at the bottom of the page (query field).
- The display settings and the field for selecting the desired text can be found on the right side of the upper box.
- The query (which can be seen in the query field) is executed by pressing the Submit button.
- There are two units in the bottom right corner of the upper box (Editing mode and Gap) which control the assembly of the query. These will be discussed later (see Section 2.4.).
1.3. How to use the interface
By default, the OHC interface should be used in the order presented on the figure above. Please follow these steps:
- Specify one or more features of the word you are looking for. After that, press the OK button.
- The corresponding query appears in the query field. Here it can be edited before it's executed. In case you are familiar with the query language, feel free to create the query directly in this field. (A guide to the query language is available via the link above the query field.)
- Before running the query, set the display parameters and the desired text (if you want to limit your search to a single text in the corpus).
- Finally, press the Submit button to run the query. Please note that if the query field is empty, you won't get any results, even if you set some parameters in the upper box. To avoid this, don't forget to press the OK button after setting the features of the word you are looking for.
The result of the query is displayed in a new window.
2. Detailed description
2.1. Features
The corpus can be thought of as a series of word forms (and punctuation marks). Each word form has numerous attributes. These can be queried in any combination. The result of the query is a list of found words (hits).
The texts in their original form (marked with o) make up the basis of the corpus. The normalised form (marked with n) is only available for a subset of the corpus. In addition, some texts have morphological annotation (marked with a), meaning that the stem and morphological analysis of the normalised form are available as well. The list of the morphological codes applied in the morphological annotation is available via the Morph link. You can see if a text has normalised version (n) or even an annotated version (a) in the drop-down menu next to the Text label.
The Interpretation, Verbal prefix (a detached verbal prefix/preverb/verbal particle which is connected to its verb) and Remark fields are filled in only in some cases.
You can use the drop-down menus next to the labels to specify whether the given string is the start/ending/part of a word form. Regular expressions can also be used in the text fields. The special characters occurring in the original form can be selected from the drop-down menu placed to the right of the Original field. This list contains all the special characters of the corpus.
2.2. Display and text selection
The Format field allows to choose how the hits should be displayed by the query interface. The frequency list can only be made from the result words, the context of the word is ignored here. In the case of concordance, each hit is shown with its context, one below another, and its exact position in the corpus is marked as well.
At the Display field, you can choose what kind of attributes you are interested in, from those which are assigned to the word forms of the corpus. By default, all information is displayed in tabular form. If you would like to get a text which is easier to read/copy/print, you may want to choose only one attribute, usually the original form.
The Context field makes it possible to view a larger context of an already found passage. In order to use this function correctly, you need to enter the ID of the given passage in the Identifier field.
Using the Text field, the search can be restricted to a given text. Codices are listed in the first place, followed by the Middle Hungarian Bible translations and other shorter texts.
2.3. Components of the concordance
The figure below shows the beginning of a concordance which contains word forms starting with megk (query: start of the original form = 'megk').
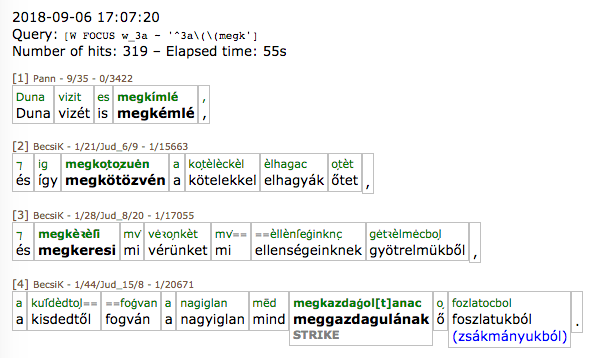
The header contains the date, the query itself, the number of hits, the run time and the results with their contexts. In the header of each hit, data identifying the exact location (locus) are displayed. These are from left to right the following: the serial number, the ID of the text (the list of the IDs are available via the Text link), the locus markers characteristic of the given text (separated by /) and finally, the ID of the word.
As a result, the desired features are displayed in tabular form (in the figure above, these features are the original and normalised forms). The keyword is marked with boldface. The double equal mark (==) in the third hit means that the original text contains two words which were written together and got divided during the normalisation process. Similarly, the original division is marked by double at-sign (@@).
2.4. Multi-word query
So far, you have seen queries that looked for one word or a phenomenon in one word. However, it's often needed to create queries which are more complex, consisting of multiple words or aiming to find multiple words.
Creating queries which consist of several units is possible due to the assembly control units located in the bottom right corner of the upper box (see Section 1.2., figure, the component marked with 5.).
The default setting of Editing Mode is 'overwrite'. In this case, pressing the OK button will overwrite the query field, so you can enter and run a new query. By selecting 'add', the existing query will be completed with the new part. In this way, it is possible to create queries consisting of multiple units. The Gap option allows the creation of multiple-unit queries where the specified units do not stand close to each other, meaning that others can occur between them.
Bálint Sass
Ágnes Kalivoda
Eszter Simon
September 6, 2018